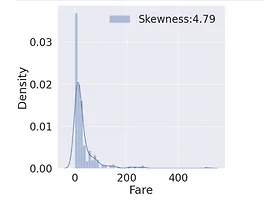
 08. EDA - Fare
흠냐리^^^,,, 백만년만의 타이나틱,, 사실 코딩도 해본지 거의 한 달이 넘은듯,,!!! ^ㅠ^,,,이노 면접보고 아주 뒤숭숭해서 손에 잡히지가 않는다.. 빨리 결과 나왔으면 좋겠다. 이번주 + 다음주안에 타이타닉을 끝내고, 마지막 자기주도 PJT 데이에, 반도체 데이터 분석에 참가해보는 게 목표긴한데 흠냐뤼,,, 열정이 다 사라졌다,,, 내 열정 찾아조,, 본격적으로 EDA의 마지막이다! Fare, Cabin, Ticket의 영향을 파악해보는 것으로 각 항목별 생존율에 미치는 영향은 파악 끝! 1. Fare 0.1~ 부터 continous한 데이터이다. fig, ax =plt.subplots(1,1,figsize=(8,8)) g = sns.distplot(df_train['Fare'], color='..
08. EDA - Fare
흠냐리^^^,,, 백만년만의 타이나틱,, 사실 코딩도 해본지 거의 한 달이 넘은듯,,!!! ^ㅠ^,,,이노 면접보고 아주 뒤숭숭해서 손에 잡히지가 않는다.. 빨리 결과 나왔으면 좋겠다. 이번주 + 다음주안에 타이타닉을 끝내고, 마지막 자기주도 PJT 데이에, 반도체 데이터 분석에 참가해보는 게 목표긴한데 흠냐뤼,,, 열정이 다 사라졌다,,, 내 열정 찾아조,, 본격적으로 EDA의 마지막이다! Fare, Cabin, Ticket의 영향을 파악해보는 것으로 각 항목별 생존율에 미치는 영향은 파악 끝! 1. Fare 0.1~ 부터 continous한 데이터이다. fig, ax =plt.subplots(1,1,figsize=(8,8)) g = sns.distplot(df_train['Fare'], color='..
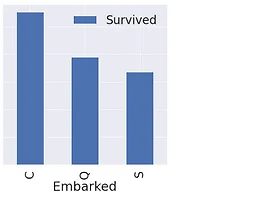 05.EDA-Embarked
05.EDA-Embarked 엥..모야...tistory바뀌었네? 백만년만의 타이타닉 ^6^,, 난 나태한 내자신에게 그래도 까먹지 않아서 다행이라고 칭찬해줘야겠다^^,, 들어가기 앞서서 이번 eda부터는 뭔가 이제 예전 분석들을 통해서, 우리으ㅣ 가설? 이 맞았던걸 확인할 수 있어어 매우 기뻤다! 1. Embarked 생존율 f,ax = plt.subplots(1,1,figsize=(7,7)) df_train[['Embarked','Survived']].groupby(['Embarked'],as_index=True).mean().sort_values(by='Survived',ascending=False).plot.bar(ax=ax) C가 가장 높..
05.EDA-Embarked
05.EDA-Embarked 엥..모야...tistory바뀌었네? 백만년만의 타이타닉 ^6^,, 난 나태한 내자신에게 그래도 까먹지 않아서 다행이라고 칭찬해줘야겠다^^,, 들어가기 앞서서 이번 eda부터는 뭔가 이제 예전 분석들을 통해서, 우리으ㅣ 가설? 이 맞았던걸 확인할 수 있어어 매우 기뻤다! 1. Embarked 생존율 f,ax = plt.subplots(1,1,figsize=(7,7)) df_train[['Embarked','Survived']].groupby(['Embarked'],as_index=True).mean().sort_values(by='Survived',ascending=False).plot.bar(ax=ax) C가 가장 높..
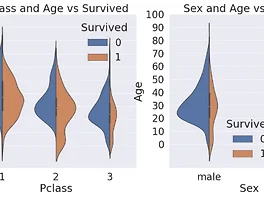 04-2 EDA Age, Sex, Pclass
04-2 EDA Age, Sex, Pclass 3차원 data를 plot하는 것은 다양하지만 여기서 우리는 :violin: violin plot을 사용한다 x축에는 우리가 구분해서 보고싶어하는 case인 (Pclass, Sex)이고, 그에따른 나이 분포를 y축으로 설정하고 hue는 생존율로 주어준다. f,ax = plt.subplots(1,2,figsize=(18,8)) sns.violinplot('Pclass','Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[0]) ax[0].set_title('Pclass and Age vs Survived') ax[0..
04-2 EDA Age, Sex, Pclass
04-2 EDA Age, Sex, Pclass 3차원 data를 plot하는 것은 다양하지만 여기서 우리는 :violin: violin plot을 사용한다 x축에는 우리가 구분해서 보고싶어하는 case인 (Pclass, Sex)이고, 그에따른 나이 분포를 y축으로 설정하고 hue는 생존율로 주어준다. f,ax = plt.subplots(1,2,figsize=(18,8)) sns.violinplot('Pclass','Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[0]) ax[0].set_title('Pclass and Age vs Survived') ax[0..







